Sequential Recommendation with Graph Neural Networks
摘要
为什么要生成密集的聚类在兴趣图中?
cluster-aware和query-aware是什么?加一个aware代表什么?
什么是图池化graph pooling
图池化就是将图分为不同子图,每个子图进行合并或者取重要的节点,来代替原来的子图。
引言
为了区分传统的推荐模型,他们往往都是在静态的用户行为上建模,而序列推荐捕捉的是用户的动态行为。以前的工作用RNN进行建模用户行为,缺点就是只能捕获短期行为序列,很难建模长期的行为,最近的一些工作就是将长期和短期兴趣进行联合建模,避免forgetting long-term兴趣。
我们提出了图卷积网络取提取隐形偏好信号,动态的图池化用来捕捉动态的偏好。
方法
什么是interest graph?
我们将SURGE模型分成了四个部分。
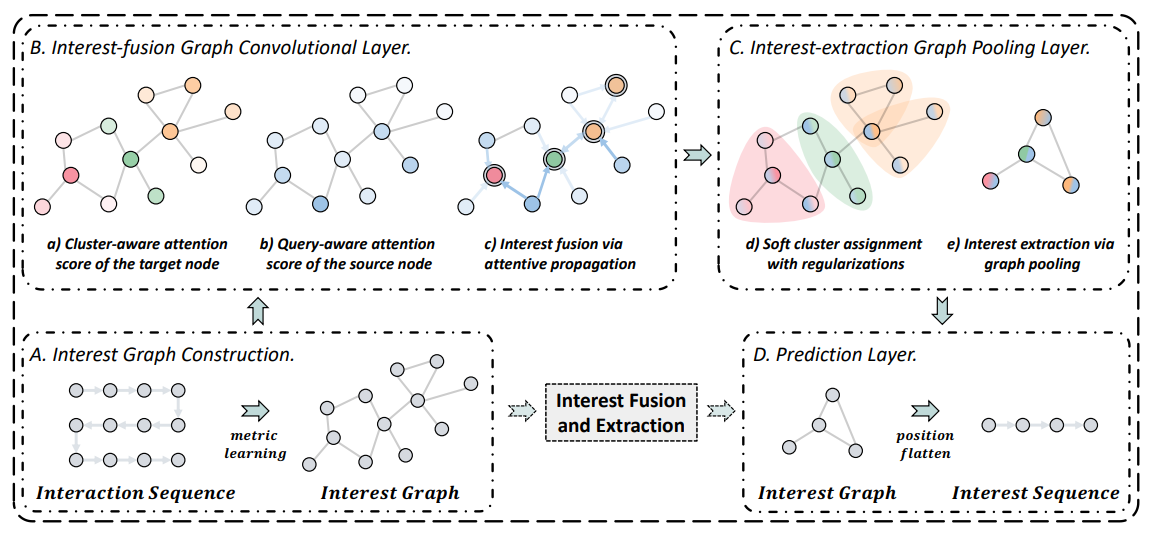
第一部分interest graph construction
将稀疏的item序列构建成item-item 基于metric learning的interest graphs。
为了整合和区分不同基于用户丰富的历史行为类型的偏好,将零散的iem序列转换成item-item 兴趣图。挑战是太过稀疏,很难转换成共现关系,难以对每个用户产生连接图,在这个部分,作者提出一个基于metric learning的新方法,自动得将每个交互序列组建成图结构取探索兴趣的分布。
我们旨在学习邻接矩阵A,每个边代表item i和j的连接。
最重要的兴趣有更高的degree相比边界的兴趣节点,因为他们连接了更多的相似的兴趣,一个先验的框架产生了,邻居节点是相似的,稠密的子图是用户的核心/重要兴趣。
节点相似metric学习
通常的metric learning应该是可以被分类成kernel-based 和attion-based mothods
通常kernel-based方法包括余弦相似度,欧氏距离,和Mahalanobis distance。一个好的相似度metric function应该是可以去学习的以至于提升表达能力以及有合理的复杂度。
为了平衡可以表达能力和复杂性,我们采取加权余弦相似度。我们的metric function可以用公式表达为。 \(M_{i j}=\cos \left(\overrightarrow{\mathbf{w}} \odot \vec{h}_{i}, \overrightarrow{\mathbf{w}} \odot \vec{h}_{j}\right)\)
其中$\odot$ 的表示hadamard乘积,$\overrightarrow{\mathbf{w}}$ 表示一个可训练的权值向量,用来适应性的强调item的不同维度的embedding hi和hj。可学习的图结构不停地使item embedding的更新。
为了增加表现力和学习过程地稳定性,metric function可以被扩展成多头metric。然后我们可以扩展一下多头的,把其演变为最终的相似性方程: \(M_{i j}^{\delta}=\cos \left(\overrightarrow{\mathbf{w}}_{\delta} \odot \vec{h}_{i}, \overrightarrow{\mathbf{w}}_{\delta} \odot \vec{h}_{j}\right), \quad M_{i j}=\frac{1}{\delta} \sum_{\delta=1}^{\phi} M_{i j}^{\delta}\) 每个头${\delta}$ 都代表这隐含地捕捉了不同语义的特征。
我们采用relative ranking strategy of the entire graph。 我们将M中小鱼非负阈值的给mask掉,设置为0.通过排序M中的metric value,我们可以得到 \(A_{i j}= \begin{cases}1, & M_{i j}>=\mathbf{R a n k}_{\varepsilon n^{2}}(M) \\ 0, & \text { otherwise }\end{cases}\) rank函数返回排序后前en^2位的值。其他的为0。
不同于absolute threshold strategy of the entire graph [5] 和relative ranking strategy of the node neighborhood [4, 19]. 前者如果超参设置的不妥当,那么这个emebdding不断地更新之后,metric value分布也将改变,也许不太可能产生一个图或者产生一个完整的图。后者返回的是一个邻接矩阵的每一行的固定数目的最大值的索引。这个使得生成图有同样的度。强制同样的稀疏分布将会使得下游GCN不可以取完整的理由图的密集或者稀疏结构信息。
第二部分interest-fusion graph convolutional layer
增强重要的行为的,削弱噪音行为
我们提出了cluster- and query-aware graph attentive convolutional layer可以收到用户的核心兴趣。位于cluster中心的item。
can perceive the user’s core interest (i.e., the item located in the cluster center) and the interest related to query interest (i.e., current target item)
这句话什么意思?什么是query interest?
输入是用户交互序列的节点长度,这一层产生一个新的节点embedding martix。作为其潜在的不同维度的输出。
**计算对齐评分Eij,将目标节点vi的重要性映射到其邻居节点vj上 **(不懂)
一旦获得了对齐评分,使用归一化注意系数对它们对应的embedding进行加权组合,
\(\vec{h}_{i}^{\prime}=\sigma\left(\mathbf{W}_{\mathbf{a}} \cdot \text { Aggregate }\left(E_{i j} * \vec{h}_{j} \mid j \in \mathcal{N}_{i}\right)+\vec{h}_{i}\right)\)
这个aggregate 可以是mean,sum max GRU等等。本论文使用简单sum方程,为了稳定attention机制的学习过程,我们采用了多头注意力,准确来说,多头独立注意力机制执行了以上的变换,他们的embedding被下列的输出所拼接。
\(\vec{h}_{i}^{\prime}=\|_{\delta=1}^{\phi} \sigma\left(\mathbf{W}_{\mathbf{a}}^{\delta} \cdot \text { Aggregate }\left(E_{i j}^{\delta} * \vec{h}_{j} \mid j \in \mathcal{N}_{i}\right)+\vec{h}_{i}\right),\)
Eij是通过多头获得的归一化的注意力系数 什么是注意力系数?。Wa是对应的线性变化权重矩阵。
Cluster- and query-aware attention
为了增强重要的信号和减弱噪音,提出了cluster和query aware注意力机制,使用注意力系数取重新分布消息传递过程中边的信息,注意力机制主要考虑两点:
首先,我们假设Vi的邻居将形成聚类,然后Vi是聚类的中心,我们定义目标节点Vi的K-hop定义为cluster的感知域。在聚类中所有节点的embedding的平均值代表一个聚类的平均信息,取鉴别这个目标节点是否是聚类的中心,这个目标节点的embedding和他的聚类embedding通常被用于计算下类的attention score。 \(\alpha_{i}=\text { Attention }_{c}\left(\mathbf{W}_{\mathbf{c}} \vec{h}_{i}\left\|\vec{h}_{i_{c}}\right\| \mathbf{W}_{\mathbf{c}} \vec{h}_{i} \odot \vec{h}_{i_{c}}\right)\) Wc是变换矩阵,II是拼接操作,点积是Hadamard乘积,也就是两个向量或者矩阵,每个对应的元素进行相乘。在我们的实验里,attention机制的attetionc是一个两层的前馈神经网络。LeakyReLu作为激活函数。
为了服务下游动态池化方法和学习用户对于不同目标兴趣的 interest’s independent 发展演变,源节点embedding hj和目标item embedding ht的关联也应该被思考,如果源节点和query item更加相关,那他的权重在对目标节点的聚合过程中更加重要。 \(\beta_{j}=\text { Attention }_{q}\left(\mathbf{W}_{\mathbf{q}} \vec{h}_{j}\left\|\vec{h}_{t}\right\| \mathbf{W}_{\mathbf{q}} \vec{h}_{j} \odot \vec{h}_{t}\right)\) Wq是一个变化矩阵,在我们的实验中,注意力q是两层的前馈网络,同样也应用LeakyReLu.
我们将目标节点的cluster分数和源节点的query score分数相加作为source node j对于target node i的权重,为了让系数更容易地有可比性在不同地节点上,我们采用了softmax 方程,取正则化他们,注意力系数Eij is computed as: \(E_{i j}=\operatorname{softmax}_{j}\left(\alpha_{i}+\beta_{j}\right)=\frac{\exp \left(\alpha_{i}+\beta_{j}\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(\alpha_{i}+\beta_{k}\right)},\)
节点i地邻居Ni包括了节点i,在自循环传播? 这是什么? (when i equels j)ai控制目标节点接受多少信息,Bj控制源节点发送多少信息。
第三部分interest-extraction graph pooling layer
动态的图池化旨在适应性的动态保留激活的核心偏好。
通过对图结构粗化,稀疏的兴趣被转换成了稠密的兴趣。
为了做图池化,a cluster assignment matrix is necessary。 cluster assignment是给不同得节点分配不同得聚类,不同节点在不同聚类有不同的概率。
我们使用GNN去产生分配矩阵。 \(S_{i:}=\operatorname{softmax}\left(\mathbf{W}_{\mathbf{p}} \cdot \text { Aggregate }\left(A_{i j} * \vec{h}_{j}^{\prime} \mid j \in \mathcal{N}_{i}\right)\right)\) 权重矩阵Wp的输出维度 对应cluster m的最大数字,softmax方程被用于预测第i个节点的被分到m cluster的可能性,值得注意的是我们可以通过SAS获得池化的邻接矩阵。
重复上面这个等式可以执行多层的池化。
Assignment regularion
仅使用梯度信号是很难训练cluster assignment matrix S. 非凸优化问题很容易让这个变成局部最优,在早期的训练阶段,本文采取了三种regularization方法。
第三种方法,Relative position regularization
用户在池化的前后需要保证用户的时间顺序,然而在pooled culster embedding martix 上swapping the index的操作的事不可微的,所以我们发明了Relative position regularization。确保cluster在pooling中的时序顺序。 \(L_{\mathrm{P}}=\left\|P_{n} S, P_{m}\right\|_{2}\) 最小化L2 norm让S中非零元素的位置更加接近主对角元素,
直觉来说,原始序列在前的节点,cluster的位置index也在前。but 啥是cluster的position index。 \(\vec{h}_{g}=\operatorname{Readout}\left(\left\{\gamma_{i} * \vec{h}_{i}^{\prime}, i \in \mathcal{G}\right\}\right)\) Readout这里是sum. 确保排列的不变性。
第四部分prediction layer
在图池化被拉平成reduced sequences后,作者建模了增强的进化的兴趣信号? we model the evolution of the enhanced interest signals是什么意思?预测下一个用户最有可能Interact的item。
什么是reduced sequences? 怎么拉平的?
仅仅考虑readout操作是不会考虑到重要兴趣之间的变化。无疑造成了时序偏见。
为了将最后的兴趣的表示添加相对的历史信息。思考不同的兴趣之间的时序关系也是很重要的。 \(\vec{h}_{s}=\operatorname{AUGRU}\left(\left\{\vec{h}_{1}^{*}, \vec{h}_{2}^{*}, \ldots, \vec{h}_{m}^{*}\right\}\right)\) GRU克服了RNN的梯度消失的问题,并且快于LSTM。而且为了让fused interest 的重要性权重更好的使用,我们采取了attentional update gate GRU。无缝的混合GRU和注意力机制。[45Deep interest evolution network for click-through rate prediction]
AUGRU能让不相关的兴趣在hidden state中造成更少的影响。避免了兴趣drifting的干扰,我理解drifting就是不稳定的兴趣。
我们将interest extraction layer and evolution output of the interest evolution layer的graph level representation作为用户的当前兴趣。
拼接的稠密表示向量,全连接层被自动地学习embedding的混合。
我们使用两层的前馈神经网络作为预测方程去评估用户在下一刻交互item的可能性, \(\hat{y}=\operatorname{Predict}\left(\vec{h}_{s}\left\|\vec{h}_{g}\right\| \vec{h}_{t} \| \vec{h}_{g} \odot \vec{h}_{t}\right)\) 所有被比较的模型都用了这个流行的预测方程,借用真实工业使用CTR预测,我们使用负对数似然方程作为损失函数,就跟所有被比较的模型一样, \(L=-\frac{1}{|O|} \sum_{o \in O}\left(y_{o} \log \hat{y}_{o}+\left(1-y_{o}\right) \log \left(1-\hat{y}_{o}\right)\right)+\lambda\|\Theta\|_{2}\) O是训练集,|O|是训练instrances的个数,$\Theta$ 表示可训练的参数,$\lambda$ 控制惩罚力度。
实验
- 我们是怎么比较最好的序列推荐的
- 我们可以有效的处理不同长度的推荐吗啊
- 这个方法的不同组件有什么不同的影响
这个实验用了淘宝和快手的数据集
淘宝用了2017年十一月25到十二月3号的数据,并且过滤掉了低于10个交互物品的用户,我们使用头七天作为训练集,后面第8天作为验证集,最后一天作为测试集。 到了50就截断
快手的是2020年10月22到10月28,也是筛掉了10个以下的用户和视频。 到了250 就截断
看了一下【20】文献,同样也是用淘宝的,但是是只是向下截断200条。
用了四种metrics
AUC 正样本分数高于负样本分数几率,反映了分类模型的rank 样本的能力。
GAUC 执行了每个用户AUC的权重平均。权重是点击数
MRR 正确答案的排名的倒数的平均,

NDCG@K 分数高得排在前面,指标就越高。 这里跟其他的现存的工作一样,K取个2。
值得注意的是session recommendation是另一种类似于序列推荐的推荐任务,只不过他们只用了用户当前的session data没有利用long-term偏好的数据。
超参设置
Adam优化,初始学习率0.001 batch size 500, embedding size 40, Xavier初始化来初始化参数。使用网格搜索取寻找最好的超参。All regularization coefficients are searched in [1e −7 , 1e −5 , 1e −3 ].The pooling length of the user interaction sequence is searched in [10, 20, 30, 40, 50] for Taobao dataset and [50, 100, 150, 200, 250] for Kuaishou dataset。 pooling length是什么东西?
序列推荐虽好,但是有一个问题,就是基于RNN的序列推荐,当处理更长的数据集时,很容易忘记long-term 兴趣序列,另外长序列包含更多的噪音,DIEN相比于GRU4REC模型更加不稳定,即使两层的GRU结构更有效,但是遇到长的序列。很容易受到噪声的影响,因此证明了我们使用metric learning的动机。
联合训练长和短term的兴趣不会累加起来产生更好的表现。
Sli-Rec 结合了长期和短期的兴趣,在Taobao上是AUC最好的Baseline了,但是对于其他的RANKING metric,他们的表现很差。
Related Work
我们认为序列行为只是反映了微弱的偏好信号,用户偏好的一部分在某个